Binary Ninja Guide
PhD Research on Rust Binary Analysis and Malware Detection
View on GitHubBinary Ninja Guide
This page provides useful tips to kickstart the journey of binary analysis in Binary Ninja.
Table of Contents
- Curly Brackets in Binary Ninja Disassembly
- Types of Annotations in Disassembly in BN
- xmmword Explained
- Why Rust Binary Uses xmmword
- References
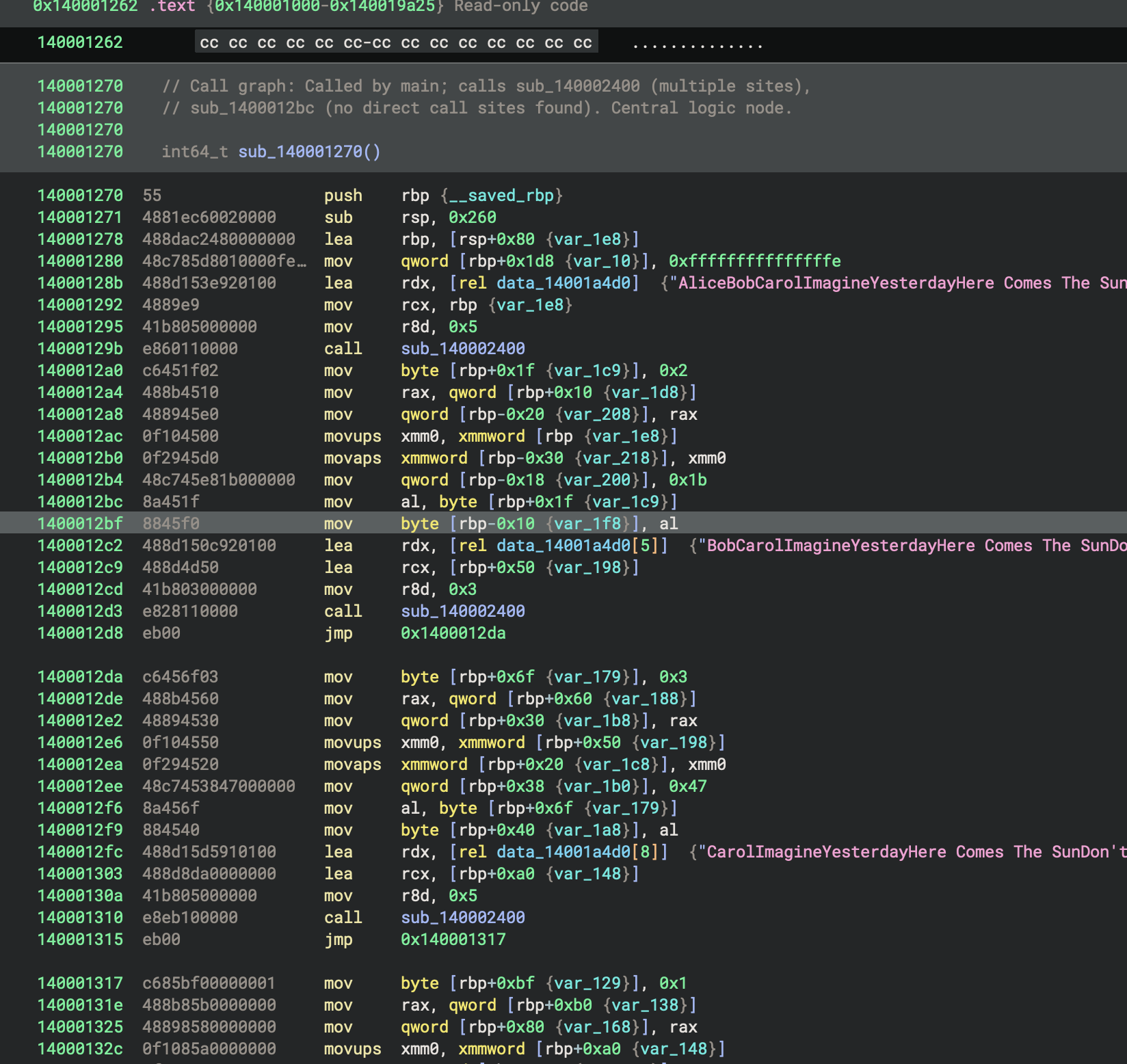 Figure 1:
Figure 1: main function in basic_pl_concepts-x86_64-cargo-build-debug.exe
Curly Brackets in Binary Ninja Disassembly
The curly brackets in Binary Ninja’s disassembly output serve as annotations that show type information and variable names that the decompiler has inferred for that memory location.
In this specific instruction:
mov qword [rbp+0x1d8], 0xfffffffffffffffe
The {var_10} annotation indicates that Binary Ninja has identified that the memory location at [rbp+0x1d8] corresponds to a local variable that it has named var_10.
Why this is useful:
-
Cross-referencing: It helps you correlate the assembly code with the decompiled C code view, where you’ll see
var_10used as a variable name -
Type context: The curly brackets show Binary Ninja’s analysis of what the code is doing at a higher semantic level
-
Navigation: In Binary Ninja’s UI, these annotations are typically interactive - you can click on them to navigate or see more information about the variable
Other annotations corresponding to other variables
{var_1e8},{var_10},{var_1c9},{var_1d8}, etc. are all local stack variables{var_208}appears to be another stack variable being accessed- The offset values (like
0x1d8,0x80,0x1d8) are the actual memory offsets from the base pointer (rbp)
These annotations make the assembly code much more readable by bridging the gap between low-level assembly and higher-level understanding of the program’s logic.
How I Know They’re Stack Variables
1. They’re accessed relative to rbp (base pointer)
In Figure 1, every variable annotation appears with rbp as the base:
mov qword [rbp+0x1d8 {var_10}], 0xfffffffffffffffe
lea rbp, [rsp+0x80 {var_1e8}]
mov byte [rbp+0x1f {var_1c9}], 0x2
In x86-64 calling conventions:
rbp= base pointer (points to the current function’s stack frame)- Local variables are stored at offsets from
rbp - Positive offsets (
rbp+0x...) typically access the previous stack frame or parameters - Negative offsets (
rbp-0x...) access local variables in the current frame
2. Function Prologue Pattern
At the start (address 140001270):
push rbp ; Save old base pointer
sub rsp, 0x260 ; Allocate stack space for local variables
This is the classic function prologue that allocates stack space for local variables. The 0x260 bytes allocated is where all these variables live.
Binary Ninja’s Naming Convention: var_XXX
Key insight: Binary Ninja names variables based on their offset FROM THE BASE POINTER, NOT their actual memory address.
The Naming Pattern:
var_N = variable at offset N from rbp
But there’s a trick: Binary Ninja uses the ABSOLUTE value of the offset for naming:
[rbp+0x80]→{var_1e8}[rbp+0x1d8]→{var_10}[rbp+0x1f]→{var_1c9}
But wait,
how does
rbp+0x1d8becomevar_10?
The Calculation:
Binary Ninja calculates the offset from the bottom of the stack frame:
- Stack space allocated:
0x260bytes (fromsub rsp, 0x260) - For an access at
[rbp+0x1d8]:- This is actually accessing data above
rbp(in the caller’s frame or parameters) - But BN needs to track it relative to the function’s frame
- This is actually accessing data above
Re-examining the Pattern:
Looking more carefully:
[rbp+0x80]is labeled{var_1e8}[rbp-0x30]is labeled{var_218}[rsp+0x80]is also labeled{var_1e8}
I notice that rsp and rbp are being used somewhat interchangeably in this code.
140001271 sub rsp, 0x260
140001278 lea rbp, [rsp+0x80 {var_1e8}]
Inspection
Addr.
140001278shows:rbp = rsp + 0x80
Binary Ninja is actually calculating offsets from the original rsp (stack pointer at function entry):
- Total frame size:
0x260bytes rbpis set torsp + 0x80- Variables are named by their offset from the frame base
The Real Formula:
var_N = offset from the bottom of the stack frame
Where the frame size is 0x260, so:
var_1e8= at offset0x1e8from frame bottom (= 0x260 - 0x78)var_218= at offset0x218from frame bottom (= 0x260 - 0x48)
Why I Know They’re Local Variables
- Memory region: They’re in the stack frame allocated by
sub rsp, 0x260 - Lifetime: Only exist during this function’s execution
- Access pattern: All accessed via base/stack pointer relative addressing
- Not globals: Global variables would use
[rip+offset]or absolute addresses - Not heap: Heap data would be accessed via pointers in registers
So in summary:
I know they’re local stack variables because of how they’re accessed (rbp/rsp-relative), where they’re allocated (in the function prologue), and Binary Ninja’s naming convention that gives them
var_XXXnames based on their stack frame offset.
Types of Annotations in Disassembly in BN
Binary Ninja adds significant analysis-driven annotations to help with reverse engineering.
Here are the key differences:
1. Variable Tracking and Naming
Raw Disassembly:
mov qword [rbp-0x8], rax
lea rax, [rbp-0x20]
Binary Ninja:
mov qword [rbp-0x8 {var_8}], rax
lea rax, [rbp-0x20 {var_20}]
BN identifies stack variables and gives them consistent names throughout the function.
2. Data Cross-References
Raw Disassembly:
lea rdx, [rel 0x14001a4d0]
Binary Ninja:
lea rdx, [rel data_14001a4d0] {"AliceBobCarolImagineYesterdayHere Comes The Sun"}
BN shows you what’s actually at that address (strings, data structures, etc.)
3. Function Call Annotations
Raw Disassembly:
call 0x140002400
Binary Ninja:
call sub_140002400 // with hover info showing signature
BN names functions, shows call graphs, and can display function signatures.
4. Type Information
Raw Disassembly:
mov [rbp-0x18], 0x1b
Binary Ninja:
mov qword [rbp-0x18 {var_200}], 0x1b
The qword explicitly shows the operand size, and variable annotations help track types.
5. String and Data Previews
As you can see in Figure 1:
lea rdx, [rel data_14001a4d0[5]] {"BobCarolImagineYesterdayHere Comes The SunDo"}
BN extracts and displays string contents inline, which is incredibly helpful for understanding what the code is doing.
6. Control Flow Understanding
Raw Disassembly:
jmp 0x1400012da
Binary Ninja:
jmp 0x1400012da // shows this is a loop back or forward jump
BN analyses control flow and can show you loop structures, if-else blocks, etc.
7. Comment Generation
Figure 1 shows:
// Call graph: Called by main; calls sub_140002400 (multiple sites)
BN automatically generates comments about calling relationships, which helps understand the program structure.
8. Dead Code and Padding Detection
0x140001262 cc cc cc cc cc cc cc-cc cc cc cc cc cc cc cc ................
BN identifies and annotates padding bytes, unreachable code, and alignment.
Other BN Advantages
- SSA Form: Can show Static Single Assignment intermediate language
- HLIL/MLIL/LLIL: Multiple intermediate language levels for analysis
- Automatic Structure Recovery: Identifies structs, arrays, and complex types
- Symbol Resolution: Resolves imports/exports automatically
- Interactive Analysis: Variables and functions are clickable for navigation
All these features make Binary Ninja’s disassembly much more semantic and context-aware compared to raw disassembly, which is purely syntactic. This dramatically speeds up reverse engineering by reducing the mental overhead of tracking what each memory location and register represents.
xmmword Explained
xmmword refers to XMM register operands, which are 128-bit (16-byte) values used in x86-64’s SIMD (Single Instruction, Multiple Data) instruction sets.
Size Breakdown
Here’s how x86-64 operand sizes are named:
byte= 8 bits (1 byte)word= 16 bits (2 bytes)dword= 32 bits (4 bytes) - “double word”qword= 64 bits (8 bytes) - “quad word”xmmword= 128 bits (16 bytes) - XMM registerymmword= 256 bits (32 bytes) - YMM register (AVX)zmmword= 512 bits (64 bytes) - ZMM register (AVX-512)
Examine the Code
Looking at the code (see figure 1):
140001295 mov r8d, 0x5
14000129b call sub_140002400
140001a2a0 mov byte [rbp+0x1f {var_1c9}], 0x2
140001a4 mov rax, qword [rbp+0x10 {var_1d8}]
140001a8 mov qword [rbp-0x20 {var_208}], rax
140001ac movups xmm0, xmmword [rbp {var_1e8}]
140001b0 movaps xmmword [rbp-0x30 {var_218}], xmm0
Addr. 140001ac: movups xmm0, xmmword [rbp {var_1e8}]
- This loads a 128-bit value from the stack into the
xmm0register movups= Move Unaligned Packed Single-precision floating point- It’s reading 16 bytes starting at
[rbp]
Addr. 140001b0: movaps xmmword [rbp-0x30 {var_218}], xmm0
- This stores the 128-bit value from
xmm0to another stack location movaps= Move Aligned Packed Single-precision
What XMM Registers Are Used For
XMM registers (xmm0-xmm15) are part of the SSE (Streaming SIMD Extensions) instruction set and are commonly used for:
- Vectorised operations: Process multiple values simultaneously
- 4 × 32-bit floats
- 2 × 64-bit doubles
- 16 × 8-bit integers
- 8 × 16-bit integers
- etc.
-
Efficient memory copying: Moving 16 bytes at once (as in the code of Figure 1)
-
String operations: Fast string comparison/search
- Cryptography: AES instructions use XMM registers
In Context
In the specific code, these instructions appear to be copying data on the stack, possibly:
- Copying a structure (16 bytes)
- Moving function parameters
- Preserving register state
- Working with strings or arrays
The fact that it’s using movups (unaligned) followed by movaps (aligned) suggests it’s copying data that might not be 16-byte aligned at the source but is being stored in an aligned location.
This is a common pattern when dealing with stack-allocated structures or when optimising memcpy-like operations.
Why Rust Binary Uses xmmword
XMM registers and xmmword operations appear frequently in Rust binaries for several specific reasons related to Rust’s design philosophy and compilation strategy.
1. Efficient Memory Operations (memcpy/memmove)
Rust frequently needs to copy data on the stack, especially for:
- Move semantics: Rust moves values by default rather than copying
- Pattern matching: Destructuring structs and enums
- Function returns: Returning structs by value
LLVM (Rust’s backend compiler) optimises these operations using XMM registers:
struct Data {
a: u64,
b: u64,
}
fn pass_struct(data: Data) -> Data {
data // This often compiles to movups/movaps with xmmword
}
The compiler uses movups xmm0, xmmword [rsp+offset] instead of multiple mov instructions because moving 16 bytes at once is faster.
2. String Operations
Rust’s String and &str types contain metadata (pointer, length, capacity):
pub struct String {
vec: Vec<u8>, // Contains: pointer (8 bytes) + length (8 bytes) + capacity (8 bytes)
}
This is 24 bytes, but often the first 16 bytes (pointer + length) are moved together using XMM registers:
movups xmm0, xmmword [rsp+0x10] ; Load pointer + length
movaps xmmword [rsp+0x20], xmm0 ; Store elsewhere
3. Option<T> and Result<T, E> Enums
Rust’s enums are often larger than simple types and get moved around frequently:
let result: Result<String, Error> = some_function();
match result {
Ok(s) => { /* ... */ },
Err(e) => { /* ... */ },
}
These enum variants (which include discriminant + data) are often 16+ bytes and get moved using XMM registers.
4. SIMD Optimisations in Standard Library
Rust’s standard library uses SIMD for performance-critical operations:
- String searching and comparison
- Slice operations (sorting, searching)
- Hashing algorithms
- Iterator operations on numeric types
Example from core::slice:
// Rust's memchr implementation uses SIMD
pub fn memchr(needle: u8, haystack: &[u8]) -> Option<usize>
This compiles to code using XMM/YMM registers for parallel byte comparison.
5. Vectorised Math Operations
When you use arrays or slices of numbers, LLVM often auto-vectorises:
fn add_arrays(a: &[f32], b: &[f32], result: &mut [f32]) {
for i in 0..a.len() {
result[i] = a[i] + b[i];
}
}
This gets optimised to use addps (add packed single-precision) with XMM registers.
6. Zero-Cost Abstractions and Inlining
Rust’s philosophy of “zero-cost abstractions” means:
- Heavy inlining of functions
- Aggressive optimisation of copies
- Stack-allocated return values
All these lead to more XMM usage for efficient data movement.
7. Default Optimisations Level
Rust defaults to optimisation level 2 (-O2) in release builds, which enables:
- Auto-vectorisation
- Aggressive use of SIMD registers for memory operations
- Loop unrolling with SIMD
Example from Your Code
Looking at Figure 1:
140001ac movups xmm0, xmmword [rbp {var_1e8}]
140001b0 movaps xmmword [rbp-0x30 {var_218}], xmm0
This pattern is classic for copying a 16-byte structure. In Rust, this could be:
- Copying a
(u64, u64)tuple - Moving a
Stringheader (pointer + length) - Copying part of an enum variant
- Moving any struct that’s 16 bytes
8. Comparison with C/C++
Rust binaries tend to have more XMM operations than equivalent C code because:
- Move semantics by default: C passes pointers, Rust moves values
- Rich standard library: More optimised code paths
- More aggressive inlining: Creates more opportunities for optimisation
- Better LLVM optimisation: Rust enables more aggressive optimisation flags by default
How to Verify This
You can check what Rust is doing by:
- Looking at MIR (Mid-level IR):
rustc --emit=mir your_file.rs - Looking at LLVM IR:
rustc --emit=llvm-ir your_file.rs - Disabling optimisations:
rustc -C opt-level=0 your_file.rs # Much fewer xmmword operations
Summary:
XMM registers appear in Rust binaries because Rust’s ownership model, move semantics, and LLVM’s aggressive optimizations make it beneficial to move larger chunks of data (16 bytes) at once, rather than using multiple smaller moves. This is a feature, not a bug. It makes Rust programs faster!
References
- Intel Corporation (2024) Intel® 64 and IA-32 Architectures Software Developer’s Manual. Available at: https://www.intel.com/content/www/us/en/developer/articles/technical/intel-sdm.html (Accessed: 29 October 2025).
- Microsoft (2024) x64 calling convention. Available at: https://learn.microsoft.com/en-us/cpp/build/x64-calling-convention (Accessed: 29 October 2025).
- Vector 35 Inc. (2024) Binary Ninja API Documentation. Available at: https://api.binary.ninja/ (Accessed: 29 October 2025).
- Vector 35 Inc. (2024) Binary Ninja User Guide. Available at: https://docs.binary.ninja/ (Accessed: 29 October 2025).
- Klabnik, S. and Nichols, C. (2023) The Rust Programming Language. 2nd edn. San Francisco: No Starch Press. Chapter 4: Understanding Ownership.
- LLVM Project (2024) Auto-Vectorization in LLVM. Available at: https://llvm.org/docs/Vectorizers.html (Accessed: 29 October 2025).
- Matsakis, N. and Klock, F.S. (2014) ‘The Rust language’, ACM SIGAda Ada Letters, 34(3), pp. 103-104. doi: 10.1145/2692956.2663188.
- Rust Project (2024) The Rust Reference: Type Layout. Available at: https://doc.rust-lang.org/reference/type-layout.html (Accessed: 29 October 2025).
- Rust Project (2024) std::mem - Rust Documentation. Available at: https://doc.rust-lang.org/std/mem/ (Accessed: 29 October 2025).